Learn about RudderStack’s high-availability methodologies.
3 minute read
Any service can go down because of a hardware failure or a software bug. This document explains the engineering design and the deployment model that makes RudderStack highly available despite any failures or bugs.
Hardware Failures
We leverage Kubernetes and auto-scaling groups to handle hardware failures and stay highly available.
To recover from node failures, we recommend provisioning the nodes with an auto-scaling group.
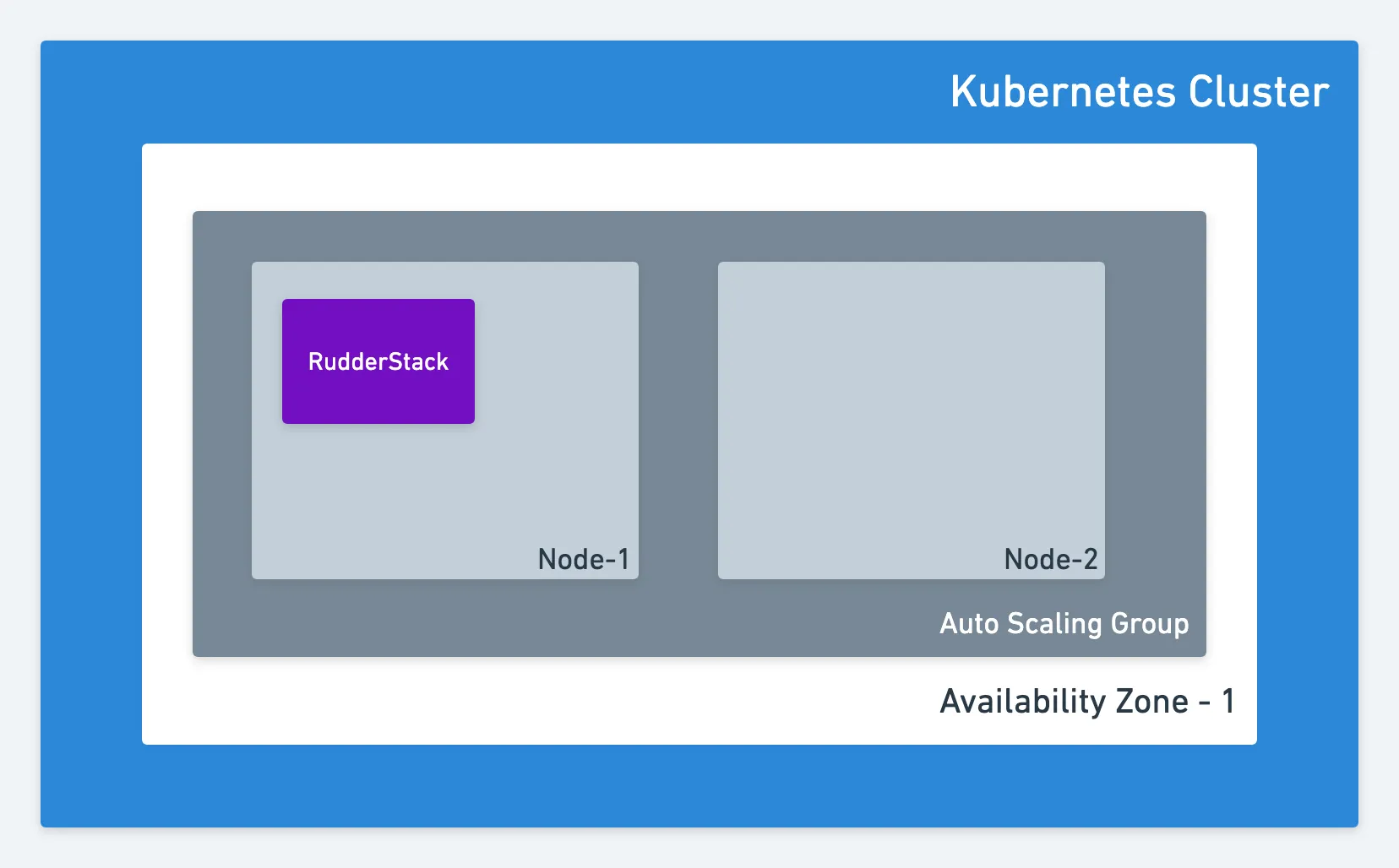
This is how a standard RudderStack production deployment looks like:
Deploying RudderStack in a Single Availability Zone
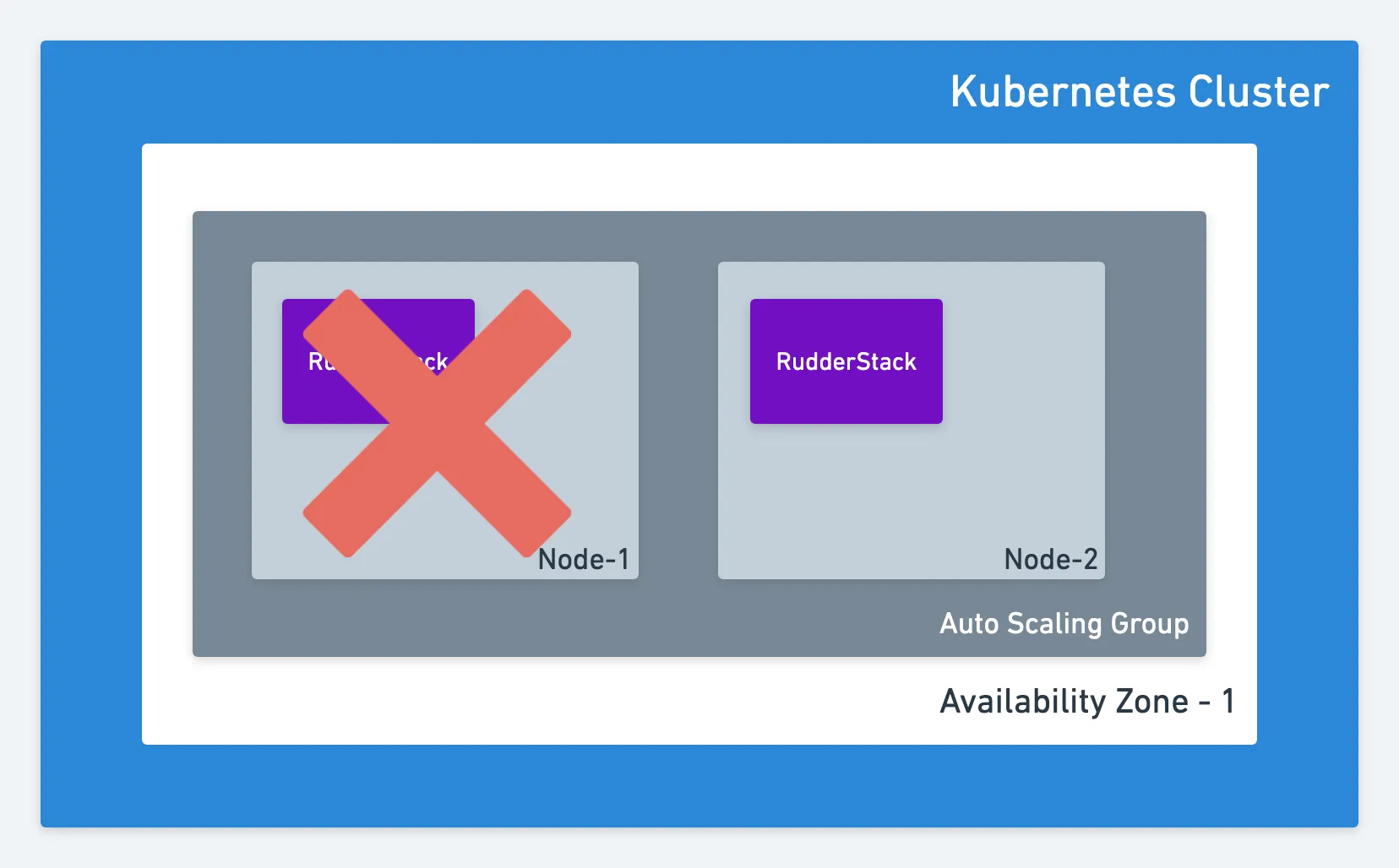
If the node hosting RudderStack goes down, Kubernetes will automatically schedule it on another available node. If you have an auto-scaling group and Kubernetes is not able to schedule RudderStack, a new node is created and RudderStack is scheduled.
Single Availability Zone
This is equivalent to the standard High Availability setup where an infrastructure team creates an extra backup node to switch the master using a heartbeat mechanism.
Deploying RudderStack in Multiple Availability Zones
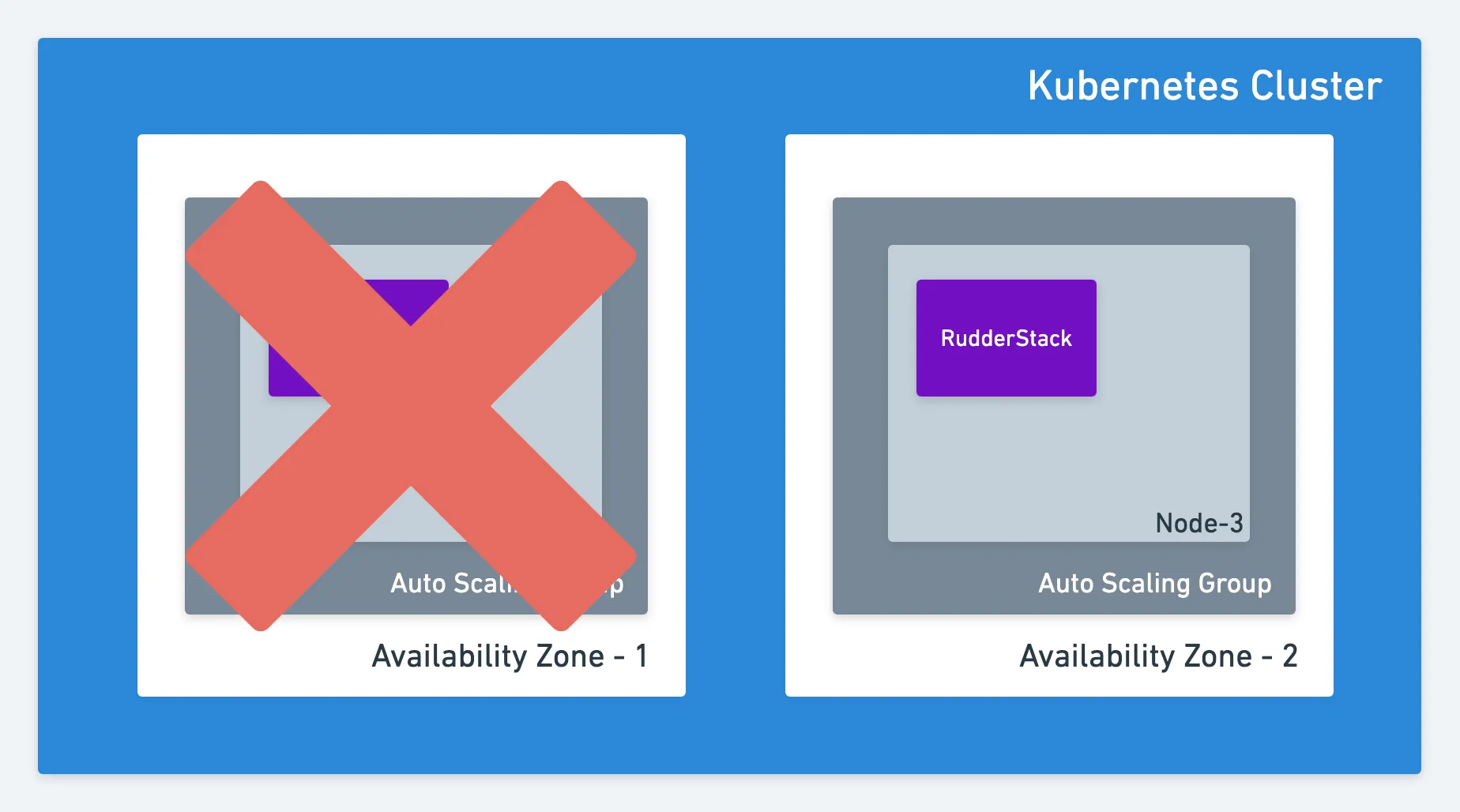
There could be instances of data center failures, where a complete availability zone can go down. If you want RudderStack to be resilient to such failures, your Kubernetes cluster should span multiple availability zones.
Multiple Availability Zones
Software Failures
RudderStack can switch between different running modes to stay resilient in case of software failures.
If RudderStack is not available, our web and mobile SDKs cache the events on the customer device and retry till they are delivered to the RudderStack server.
RudderStack Server Running Modes
RudderStack supports two running modes - normal and degraded
Normal Mode
In the normal mode, RudderStack receives events and forwards them to the destinations as usual.Normal Mode
Degraded Mode
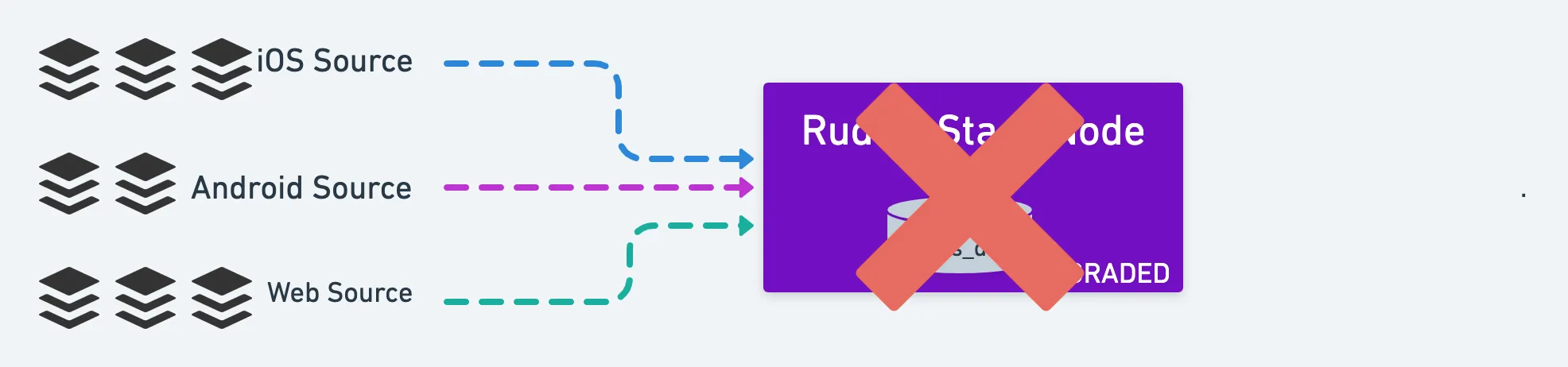
If RudderStack keeps crashing while processing the events, it enters the degraded mode after a threshold number of restarts is reached.
In the degraded mode, RudderStack receives events and stores them. It will not forward to destinations.
Degraded Mode
In this mode, all your events are completely safe and will be sent to destination maintaining the order.
If RudderStack crashes in degraded mode, we request you to send us the crash reports to identify and fix the issue.
Alerting in RudderStack
RudderStack has an in-built alerting service that will raise an alert when the server enters degraded mode. The alerting service supports integrations with PagerDuty and VictorOps. You can configure this to be alerted when an unexpected issue occurs with the RudderStack server.
Client SDK Caching
There may arise a scenario where the RudderStack service is down because of an unexpected issue, and is not reachable for the SDKs. In such a situation, the web and the mobile SDKs will then cache the events in the local storage. The pending events will be retried with a backoff and delivered once the service is available again.
Even during an unexpected downtime, all your events are safe and will be delivered to your destinations without fail.Downtime Scenario
This site uses cookies to improve your experience while you navigate through the website. Out of
these
cookies, the cookies that are categorized as necessary are stored on your browser as they are as
essential
for the working of basic functionalities of the website. We also use third-party cookies that
help
us
analyze and understand how you use this website. These cookies will be stored in your browser
only
with
your
consent. You also have the option to opt-out of these cookies. But opting out of some of these
cookies
may
have an effect on your browsing experience.
Necessary
Always Enabled
Necessary cookies are absolutely essential for the website to function properly. This
category only includes cookies that ensures basic functionalities and security
features of the website. These cookies do not store any personal information.
This site uses cookies to improve your experience. If you want to
learn more about cookies and why we use them, visit our cookie
policy. We'll assume you're ok with this, but you can opt-out if you wish Cookie Settings.