Get answers to frequently asked questions about RudderStack.
17 minute read
This section aims to address the queries and issues you might encounter while using RudderStack.
If you come across any issue not listed in this guide, feel free to start a conversation in our Slack community.
RudderStack Cloud
Which RudderStack features are not supported in Open Source?
See the RudderStack Cloud vs. Open Source guide for a detailed comparison of the features available in RudderStack Open Source and RudderStack Cloud.
Where can I see my monthly event usage/volume?
To see your monthly event usage/volume, go to Settings > Organization > Usage tab in your RudderStack dashboard.
RudderStack calculates the monthly event volume based on the events ingested at source and not the events sent to the destinations.
Filtering selective events to destinations using transformations will not result in a lower event volume.
Is there any event volume limit for RudderStack Cloud Free?
There is an event volume limit of 1000 events/minute for RudderStack Cloud Free users. You will get a 429 (rate limit exceeded) error if this limit is breached.
Is there any event volume limit for RudderStack Open Source?
An open source data plane URL looks like http:localhost:8080 where 8080 is typically the port where your data plane is hosted.
RudderStack Cloud: The data plane URL is provided in the dashboard at the top of the Connections page.
RudderStack Pro/Enterprise: Contact us for the data plane URL with the email ID you used to sign up for RudderStack.
Is it possible to change the data plane URL?
For RudderStack Cloud Free and Starter plans, the data plane URL is provided in the dashboard, at the top of the Connections page. It is is not possible to change this URL.
To get started with RudderStack on my local machine, is it mandatory to get the workspace token from RudderStack dashboard?
The workspace token is required if you are installing RudderStack in your own environment and wish to use the RudderStack-hosted control plane. It is a unique identifier for your configuration settings which RudderStack can fetch to track your instrumentations.
Yes. Use the open source Control Plane Lite utility to self-host the control plane and configure your sources and destinations. Refer to the Control Plane Lite section below for more information.
While running git submodule update, I get this error:
Please make sure you have the correct access rights and the repository exists.
fatal: clone of 'git@github.com:rudderlabs/rudder-transformer.git' into submodule path '/home/ubuntu/rudder-server/rudder-transformer' failed
Failed to clone 'rudder-transformer'. Retry scheduled.
Cloning into '/home/ubuntu/rudder-server/rudder-transformer'...
git@github.com: Permission denied (publickey).
fatal: Could not read from remote repository.
Verify if the SSH keys are correctly set in your GitHub account as they are used when cloning using the git protocol. For more information, refer to this Stack Overflow thread.
How do I verify my RudderStack installation?
You can verify your RudderStack installation by sending test events and checking if they are delivered correctly. For more information, refer to the Sending Test Events guide.
My open source RudderStack setup keeps creating a new database automatically. What could be the reason?
This can happen if you have changed your workspace token. Also, ensure that the RudderStack server is running on the latest version.
Docker
Is there any recommended size for the EC2 instance? I am running a self-hosted Docker setup.
A c4.xlarge or c4.2xlarge machine should work just fine for your setup.
I’m running RudderStack in Docker on a GCP VM instance. I upgraded the instance to have more CPU and now the RudderStack container is stuck on this message:
sh -c '/wait-for db:5432 -- /rudder-server'
This message indicates that the RudderStack server is waiting on the PostgreSQL database dependency to be up and running. Verify if your PostgreSQL container is up.
RudderStack backend (server)
How do I check the status of the RudderStack data plane?
To check the status of the data plane, run the following command:
CURL <DATA_PLANE_URL>/health
A sample command would look something like:
CURL https://hosted.rudderlabs.com/health
How many events can a single RudderStack node handle?
The number of events a single RudderStack node can handle depends on the destinations that you are sending the event data to. It also depends on the transformations you are running.
Here are some ballpark figures:
Activity
Events handled
Dumping to S3
Approx. 1.5K events/sec
Dumping to warehouse
Approx. 1K events/sec
Dumping to warehouse and a few cloud destinations
Approx. 750 events/sec
These are conservative numbers. A single RudderStack node can handle close to 5x event load at the peak— just that those events get cached locally and are drained as per the regular throughput.
How can I speed up the number of events sent to a destination?
There is a config variable to configure the number of workers that send data to destinations. The default value is 64, which itself is an aggressive number. You can increase the number of workers. However, note that some destinations generally throttle the number of requests per account.
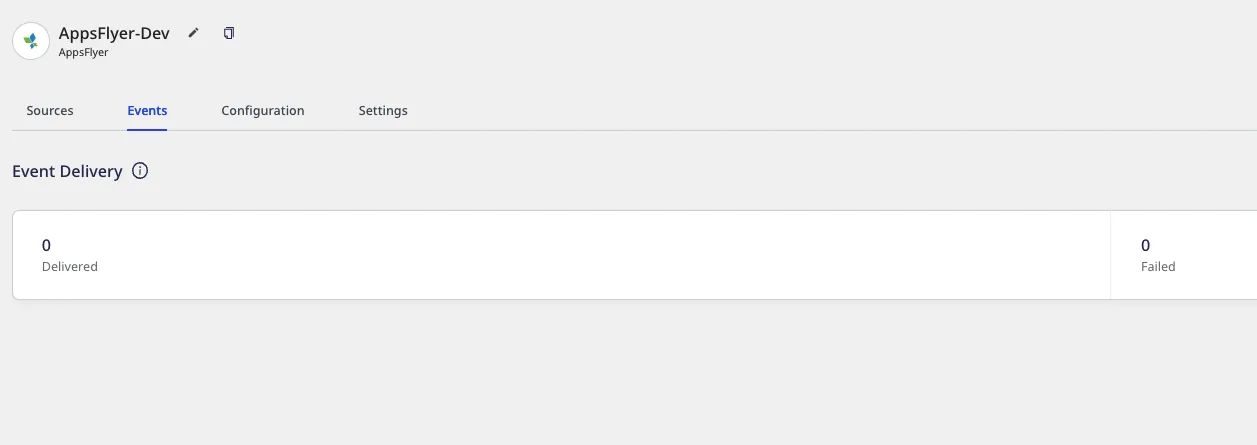
How I can know the number of events that are sent to a destination?
Go to the Events tab of the destination page to see the event-related metrics, as shown below:
Events sent through device mode are not visible in this option.
Do I need to change the data plane URL associated with the RudderStack Cloud to my self-hosted data plane?
No, you need not change the URL. As long as your self-hosted data plane has the same workspace token, the RudderStack-hosted control plane will use your data plane for processing events.
While trying to start rudder-server, I get the following error:
backend_1 | 2021/06/09 08:12:14 notifying bugsnag: During db.vlog.open: Value log truncate required to run DB. This might result in data loss
backend_1 | 2021/06/09 08:12:14 bugsnag.Notify: bugsnag/payload.deliver: invalid api key: ''
backend_1 | 2021/06/09 08:12:14 bugsnag/sessions/publisher.publish invalid API key: ''
backend_1 | panic: During db.vlog.open: Value log truncate required to run DB. This might result in data loss [recovered]
backend_1 | panic: During db.vlog.open: Value log truncate required to run DB. This might result in data loss [recovered]
backend_1 | panic: During db.vlog.open: Value log truncate required to run DB. This might result in data loss
Check for the folder /tmp/badgerdbv2 and delete it. This should resolve the issue and you should be able to start rudder-server.
I am using the Control Plane Lite to generate the workspaceConfig.json file. But when I import this file, I get this error:
TypeError: Cannot read property 'name' of undefined"
This issue can occur when you have some old data left in your browser’s local storage. Use the latest version of the Control Plane Lite after clearing your browser cache and local storage.
For a self-hosted environment, how do I obtain the control plane URL?
To use the control plane URL to initialize your SDKs, follow these steps:
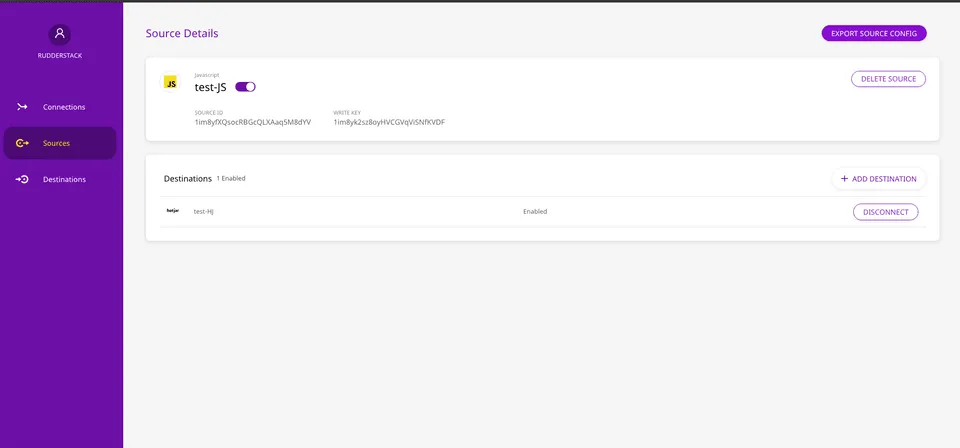
Set up the control plane using the Control Plane Lite utility.
Go to dashboard, configure the source, and export the source configuration by clicking the EXPORT SOURCE CONFIG button as shown:
Host the exported file on your own server such that the configuration is available at <CONTROL_PLANE_URL>/sourceConfig.
This solution assumes that you have already set up the RudderStack data plane (backend) locally.
I don’t want to configure my API keys and secrets with RudderStack’s control plane. But I want to use its features like Transformations. How can I do this?
RudderStack lets you provide your API keys and secrets as environment variables prepended with env. and run the data plane.
Suppose you are configuring Amazon S3 as a destination but you don’t want to enter the AWS access key credentials in the destination settings. Fill the value with a placeholder that starts with env. It should look like this env.MY_AWS_ACCESS_KEY. Then set the value of the environment variable MY_AWS_ACCESS_KEYwhile running the data plane.
Transformations
How do I add user transformations in RudderStack?
RudderStack lets you implement your own custom transformations that leverage the event data to implement specific use-cases based on your business requirements. Refer to the Adding a transformation section to add transformations in RudderStack.
Can I apply a transformation to a source configured in RudderStack?
Currently, transformations can only be configured and used for destinations. If you want to write custom logic specific to the source, you can get the Source ID in the transformation function and use it to include the logic. Refer to the Accessing metadata section for more information.
RudderStack Cloud
Can I change my workspace name?
Unfortunately, your workspace name is not changeable currently. We are planning to include this feature in our future releases.
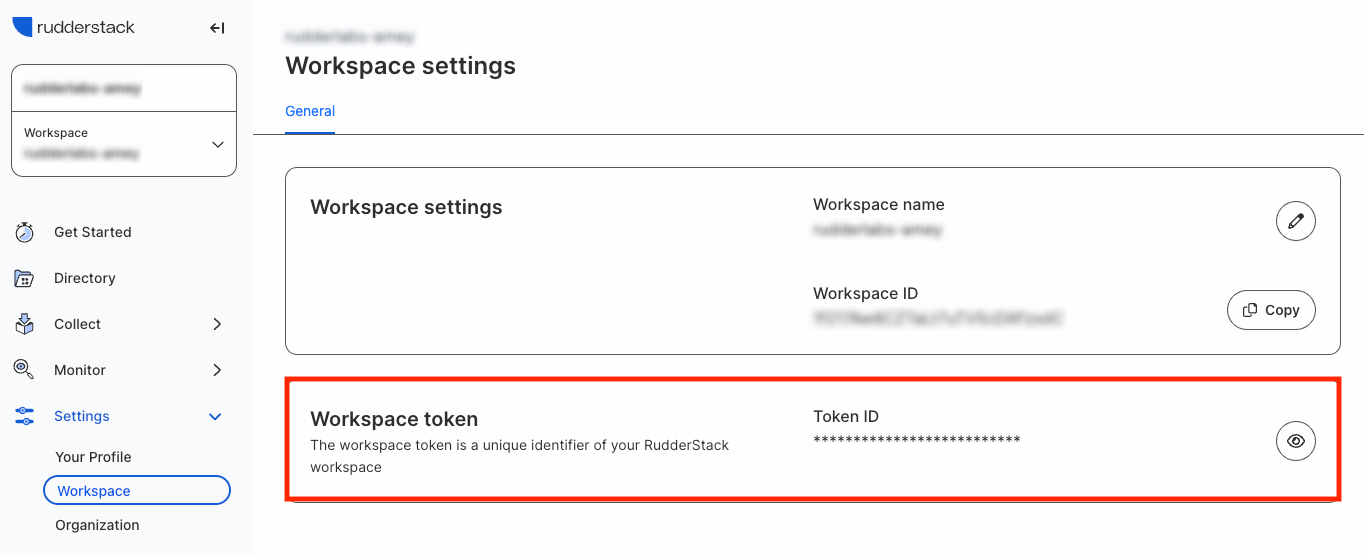
What is the difference between source write key and the workspace token?
The write key is different from your workspace token.
The write key is associated with the source and is used by RudderStack to track the events.
On the other hand, the workspace token is a unique identifier for the configuration settings which RudderStack uses to fetch and track your instrumentations. You can find it by navigating to Settings > Workspace in your RudderStack dashboard:
I see a few events that show up in the live stream but do not reach the destination. How do I see the logs or data that is sent to my destination?
To view the data or events that are sent to your destination, you can use the Live Events tab in your destination’s page.
Do I need to change the data plane URL associated with the cloud-hosted RudderStack to my self-hosted data plane?
No, you need not change the URL. As long as your self-hosted data plane has the same workspace token, the RudderStack-hosted control plane will use your data plane for processing events.
How can I switch from RudderStack Open Source to RudderStack Cloud and vice-versa?
Switching between RudderStack Open Source and RudderStack Cloud is quite straightforward. Replace the URL of your self-hosted data plane to the RudderStack-hosted data plane URL. You can use the same sources and destinations as before - all you need to do is just change the URL to where the events are sent.
What is a personal access token? Where do I find it?
The personal access token is a unique token associated with your RudderStack account. It is required to access and consume the RudderStack APIs. For more information, see Personal Access Token.
For production use cases, RudderStack recommends using a service access token over a personal access token.
You can generate a new personal access token by going to Settings > Your Profile > Account and clicking the Generate new token button.
Integrations
SDKs
I want to use the RudderStack JavaScript SDK to track impressions in an ecommerce site. How can I send the impression data in batches? I could not find the batch method in the SDK.
You should use the track method instead. For the JavaScript SDK’s track method parameters specific to ecommerce, you can refer to the Ecommerce Events Spec.
Is Shopify compatible as a data source for RudderStack?
Yes, Shopify is compatible as an event stream data source. For more information, refer to Shopify. We also have users that integrate the JavaScript SDK into their Shopify sites. In some cases, they even do it through Google Tag Manager.
However, RudderStack strongly recommends using the Shopify source integration for better tracking.
Destinations
Would a destination connected with a source work if it is connected to a new source?
Yes, you can connect a destination to multiple sources with no issues.
How do I see the logs or the data that is sent to my destination?
To view the data or events that are sent to your destination, you can use the Live Events tab on your destination page.
I would like to send events to Mixpanel via RudderStack. However, I would like to set a filtering condition on the source events before routing them to Mixpanel. How do I do this?
You can use Transformations to set custom logic on your events before sending them to Mixpanel.
I am seeing a Message type not supported error. What does this mean?
This error is being returned from the RudderStack back end. It means that a particular destination does not support the event you are trying to send.
For example, Salesforce only supports identify events. Therefore, if a track call is sent to Salesforce, the Message type not supported error will be returned. This error does not affect any other events and is harmless. However, a simple user transformation can be written to filter out these events so you will no longer see this error.
Warehouse destinations
For a comprehensive list of warehouse destinations-specific FAQ, refer to the Warehouse FAQ guide.
How can I force RudderStack to push all data to a data warehouse in real-time with no delay? During the implementation, it would be better to see how the data is collected in real-time, rather than 30 minutes later.
You can override the UI-set sync frequency by setting warehouseSyncFreqIgnore to true in config.yaml (or config.toml, in case you have an older RudderStack deployment). You can set your desired frequency by changing the uploadFreqInS parameter.
I am using RudderStack to mirror my source tables to PostgreSQL. I have all of the data in the S3 staging folders. But RudderStack doesn’t create the corresponding PostgreSQL tables when I click ‘sync’. What do I do?
Firstly, make sure you have set up the required user permissions for PostgreSQL.
Check if the database is accessible by allowlisting all RudderStack IPs listed here.
Ensure that all security group policies for S3 are set as specified here.
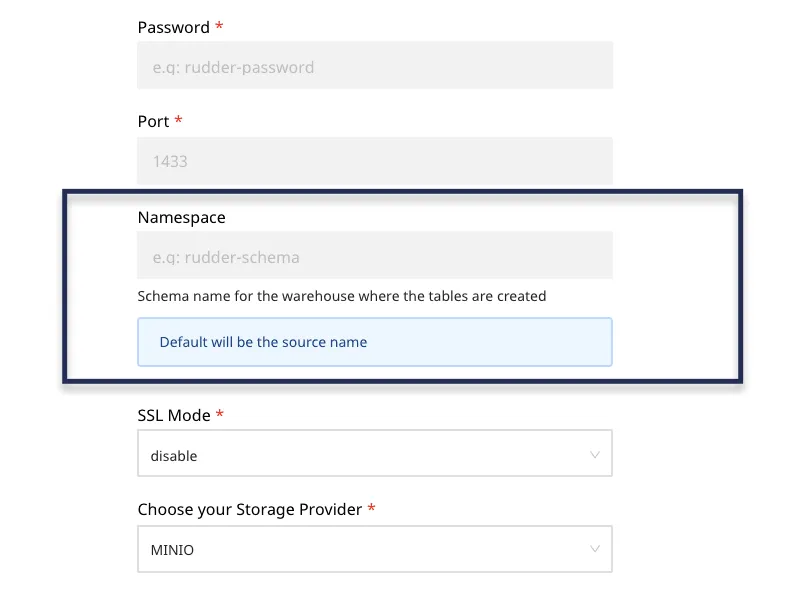
When sending data into a data warehouse, how can I change the table where this data is sent?
By default, RudderStack sends the data to the table/dataset based on the source it is connected to. For example, if the source is Google Tag Manager, RudderStack sets the schema name as gtm_*.
You can override this by setting a Namespace in the destination settings as shown:
I am trying to set warehouseSyncFreqIgnore = true to have a real-time sync with BigQuery but I can’t find the config.yaml file. How can I do this using the Docker setup?
You can do so by setting this value via the following .env variables:
RSERVER_WAREHOUSE_WAREHOUSE_SYNC_FREQ_IGNORE
RSERVER_WAREHOUSE_UPLOAD_FREQ_IN_S
I’m looking to send data to my data warehouse through RudderStack and I’m trying to understand what data is populated in each column. How do I go about this?
Refer to the Warehouse Schema guide for details on how RudderStack generates the schemas in the warehouse.
I am trying to load data into my BigQuery destination and I get this error:
backend_1 | {Location: “”; Message: “Cannot read and write in different locations:
source: US, destination: us-central1""; Reason: “invalid”}"
Make sure that both your BigQuery dataset and the bucket have the same region. For more information, refer to the BigQuery documentation.
When sending data to BigQuery, I can set the bucket but not a folder within the bucket. Is there a way to put RudderStack data in a specific bucket folder?
Yes, you can set the desired folder name in the Prefix input field while configuring your BigQuery destination. For more information, refer to the BigQuery setup guide.
RudderStack failover, hardening, and security
What cloud infrastructure is the RudderStack hosted solution running on? Do you have failover to alternate availability zones?
RudderStack’s hosted solution is running on AWS EKS with the cluster spanning 3 availability zones (east-1a, east-1b, east-1c).
How does RudderStack ensure uptime with a single node?
At the infrastructure layer, RudderStack runs on a multi-availability zone EKS cluster. So hardware failures, if any, are handled by Kubernetes by relocating pods.
At an application level, RudderStack operates in one of the following 3 modes:
Normal mode: everything is normal and there are no issues.
If for some reason the system fails (e.g. because of a bug), it enters the Degraded mode, where RudderStack processes incoming requests but doesn’t send them to destinations.
If the system continues to fail to process the data, e.g., internal database corruption, it enters Maintenance mode. In this mode we save the previous state (which can be debugged and processed) and start from scratch— still receiving requests.
All of RudderStack’s SDKs also have failure handling. They can store events in local storage and retry on failure.
RudderStack provides isolation between the data and control planes. For example, if the control plane (where you manage the source and destination configurations) goes offline, the data plane continues to operate.
All this is done to ensure that RudderStack can always receive events and no events are lost.
Would adding an additional node to RudderStack cause an outage, and if so what is the expected downtime? How long would it take to recover from backup?
Adding a new node requires a bit of downtime. However, RudderStack is built in a way that minimizes this downtime as much as possible.
When a new node is added, the users need to be rebalanced across nodes to keep event ordering in place. While the rebalancing takes place (can take a few minutes), RudderStack does not send events to downstream destinations, but continues to receive events so that your SDKs don’t see any failures, ignoring the small ELB switch over time.
Additionally, the SDKs have a built-in local caching and retrying capability. So even if there is a failure, no events are lost.
Monitoring and alerting
How do I set up alerts in my Grafana dashboard?
You can use the Grafana dashboard to set up time-critical alerts for various use cases like:
Aborted/failed events to destinations
Event volume spikes crossing a defined threshold.
The following video tutorial walks you through setting up and enabling alerts in your Grafana dashboard:
IP allowlisting
What are the IPs to be allowlisted?
To enable network access to RudderStack, allowlist the following RudderStack IPs depending on your region and RudderStack Cloud plan:
Plan
Region
US
EU
Free, Starter, and Growth
3.216.35.97
18.214.35.254
23.20.96.9
34.198.90.241
34.211.241.254
52.38.160.231
54.147.40.62
3.123.104.182
3.125.132.33
18.198.90.215
18.196.167.201
Enterprise
3.216.35.97
34.198.90.241
44.236.60.231
54.147.40.62
100.20.239.77
3.66.99.198
3.64.201.167
3.123.104.182
3.125.132.33
All the outbound traffic is routed through these RudderStack IPs.
Which URLs should be allowlisted for a content security policy?
For a content security policy, the following URLs should be allowlisted:
Control plane
https://api.rudderstack.com
https://api.rudderlabs.com
Data plane
DATA_PLANE_URL
See this FAQ for more information on obtaining your data plane URL.
SDK
https://cdn.rudderlabs.com
Retry behavior
How does RudderStack handle retries for failed events in case of destination failure?
Sometimes the downstream destination can be unavailable or send a failure code for a variety of reasons. RudderStack retries sending the events depending on the type of failure:
Failure Code
Retry Behavior
5XX, 429
Retry for a time window of 3 hours with exponential backoff and a minimum of 3 times.
4XX
Abort without any retries.
The above behavior is configurable via config variables in config.yaml.
If a user event fails, the other events are not sent until the failed event is successfully sent or aborted, as per above behavior. This is to ensure event ordering for all events from a single user.
For more information on the SDK-specific retry and backoff logic, refer to the SDK FAQ guide.
Throttling behavior
Some destinations have limits on the number of events they accept. How does RudderStack handle this?
Some downstream destinations have limits on the number of events they accept at an account or user/device level. RudderStack tries to throttle the API requests as per the destination’s limits.
This site uses cookies to improve your experience while you navigate through the website. Out of
these
cookies, the cookies that are categorized as necessary are stored on your browser as they are as
essential
for the working of basic functionalities of the website. We also use third-party cookies that
help
us
analyze and understand how you use this website. These cookies will be stored in your browser
only
with
your
consent. You also have the option to opt-out of these cookies. But opting out of some of these
cookies
may
have an effect on your browsing experience.
Necessary
Always Enabled
Necessary cookies are absolutely essential for the website to function properly. This
category only includes cookies that ensures basic functionalities and security
features of the website. These cookies do not store any personal information.
This site uses cookies to improve your experience. If you want to
learn more about cookies and why we use them, visit our cookie
policy. We'll assume you're ok with this, but you can opt-out if you wish Cookie Settings.