


Databricks Partner Connect
Connect your Databricks cluster to RudderStack and set up your Databricks Delta Lake destination.
14 minute read
Delta Lake is a popular data lake used for both streaming and batch operations. It lets you store structured, unstructured, and semi-structured data securely and reliably.
You can now use Databricks Partner Connect to set up your Databricks Delta Lake destination in RudderStack without following the setup instructions.
Find the open source code for this destination in the GitHub repository.
Before configuring Delta Lake as a destination in RudderStack, it is highly recommended to go through the following sections to obtain the necessary configuration settings. These sections also contain the steps to grant RudderStack and Databricks the necessary permissions to your preferred storage bucket.
To send event data to Delta Lake, you first need to add it as a destination in RudderStack and connect it to your data source. Once the destination is enabled, events will automatically start flowing to Delta Lake via RudderStack.
To configure Delta Lake as a destination in RudderStack, follow these steps:
For more information on obtaining the server hostname, port, and the cluster’s HTTP path, refer to the Obtaining the JDBC/ODBC configuration section below.
If you have not configured a Unity catalog, you can access the delta tables at
{path_to_table}/{schema}/{table}.If you have configured a Unity catalog, follow these steps:
- Create an external location by following this Databricks documentation. Your location will look something like
s3://{bucket_path}/{external_location}.- Specify the absolute location in the External delta table location setting. It will look something like
s3://{bucket_path}/{external_location}/{path_to_table}/{schema}/{table}.
If you do not specify the catalog name, RudderStack uses the default catalog configured for your workspace.
See How RudderStack stores data in an object storage platform for more information.
If you select S3 as your storage provider, RudderStack provides the option to specify your IAM role ARN or the AWS access key ID/secret access key by enabling the Use STS Tokens to copy staging files setting. For more information, refer to the Amazon S3 storage bucket settings section below.
The append operation helps to achieve faster data syncs while reducing warehouse costs. However, note that it may increase the number of duplicates in the warehouse, especially if the existing data is older than 7 days. A common scenario where duplication might occur is when the SDKs retry sending events in case of failures.
A merge strategy ensures deduplication but can lead to longer sync times and increased warehouse costs.
identifies table while skipping the users table. This eliminates the need for a merge operation on the users table. If toggled off, RudderStack sends the events to both the identifies and users tables.tracks table.This section contains the steps to edit your bucket policy to grant RudderStack the necessary permissions, depending on your preferred cloud platform.
Follow these steps to grant RudderStack access to your S3 bucket based on the following two cases:
Follow the steps listed in this section if the Use STS Token to copy staging files option is disabled, that is, you don’t want to specify the AWS credentials while configuring your Delta Lake destination.
If you are using RudderStack Cloud, edit your bucket policy using the following JSON:
{
"Version": "2012-10-17",
"Statement": [{
"Effect": "Allow",
"Principal": {
"AWS": "arn:aws:iam::422074288268:user/s3-copy"
},
"Action": [
"s3:GetObject",
"s3:PutObject",
"s3:PutObjectAcl",
"s3:ListBucket"
],
"Resource": [
"arn:aws:s3:::YOUR_BUCKET_NAME/*",
"arn:aws:s3:::YOUR_BUCKET_NAME"
]
}]
}
Make sure you replaceYOUR_BUCKET_NAMEwith the name of your S3 bucket.
If you are self-hosting RudderStack, follow these steps:
{
"Version": "2012-10-17",
"Statement": [{
"Effect": "Allow",
"Action": "*",
"Resource": "arn:aws:s3:::*"
}]
}
Copy the ARN of this newly-created user. This is required in the next step.
{
"Version": "2012-10-17",
"Statement": [{
"Effect": "Allow",
"Principal": {
"AWS": "arn:aws:iam::ACCOUNT_ID:user/USER_ARN"
},
"Action": [
"s3:GetObject",
"s3:PutObject",
"s3:PutObjectAcl",
"s3:ListBucket"
],
"Resource": [
"arn:aws:s3:::YOUR_BUCKET_NAME/*",
"arn:aws:s3:::YOUR_BUCKET_NAME"
]
}]
}
Make sure you replaceUSER_ARNwith the ARN copied in the previous step. Also, replaceACCOUNT_IDwith your AWS account ID andYOUR_BUCKET_NAMEwith the name of your S3 bucket.
env file present in your RudderStack installation:RUDDER_AWS_S3_COPY_USER_ACCESS_KEY_ID=<user_access_key>
RUDDER_AWS_S3_COPY_USER_ACCESS_KEY=<user_access_key_secret>
In this case, provide the configuration directly while setting up the Delta Lake destination in RudderStack:
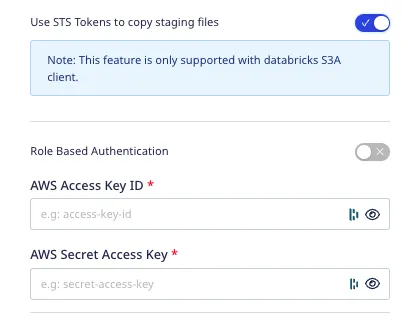
It is highly recommended to enable this setting as the access keys-based authentication method is now deprecated.
If Role-based Authentication is disabled, you need to enter the AWS Access Key ID and AWS Secret Access Key to authorize RudderStack to write to your S3 bucket.
In both the role-based and access key-based authentication methods, you need to set a policy specifying the required permissions for RudderStack to write to your intermediary S3 bucket. Refer to the S3 permissions for warehouse destinations section for more information.
You can provide the necessary GCS bucket configuration while setting up the Delta Lake destination in RudderStack. For more information, refer to the Google Cloud Storage bucket settings.
You can provide the necessary Blob Storage container configuration while setting up the Delta Lake destination in RudderStack. For more information, refer to the Azure Blob Storage settings.
This section contains the steps to grant Databricks the necessary permissions to access your staging bucket, depending on your preferred cloud platform.
Follow these steps to grant Databricks access to your S3 bucket depending on your case:
Follow the steps listed in this section if the Use STS Token to copy staging files option is disabled, i.e. you don’t want to specify the AWS access key and secret access key while configuring your Delta Lake destination.
In this case, you will be required to configure your AWS account to create an instance profile which will then be attached with your Databricks cluster.
Follow these steps in the exact order:
Follow the steps listed in this section if the Use STS Token to copy staging files option is enabled, i.e. you are specifying the AWS access key and secret access key in the dashboard while configuring your Delta Lake destination.
Add the following Spark configuration to your Databricks cluster:
spark.hadoop.fs.s3.impl shaded.databricks.org.apache.hadoop.fs.s3a.S3AFileSystem
spark.hadoop.fs.s3a.impl shaded.databricks.org.apache.hadoop.fs.s3a.S3AFileSystem
spark.hadoop.fs.s3n.impl shaded.databricks.org.apache.hadoop.fs.s3a.S3AFileSystem
spark.hadoop.fs.s3.impl.disable.cache true
spark.hadoop.fs.s3a.impl.disable.cache true
spark.hadoop.fs.s3n.impl.disable.cache true
For more information on adding custom Spark configuration properties in a Databricks cluster, refer to Spark configuration guide.
To grant Databricks access to your GCS bucket, follow these steps:
spark.hadoop.fs.gs.auth.service.account.email <client_email>
spark.hadoop.fs.gs.project.id <project_id>
spark.hadoop.fs.gs.auth.service.account.private.key <private_key>
spark.hadoop.fs.gs.auth.service.account.private.key.id <private_key_id>
For more information on adding custom Spark configuration properties in a Databricks cluster, refer to Spark configuration guide.
<project_id>,<private_key>, <private_key_id>,<client_email>.To grant Databricks access to your Azure Blob Storage container, follow these steps:
spark.hadoop.fs.azure.account.key.<storage-account-name>.blob.core.windows.net <storage-account-access-key>
For more information on adding custom Spark configuration properties in a Databricks cluster, refer to Spark configuration guide.
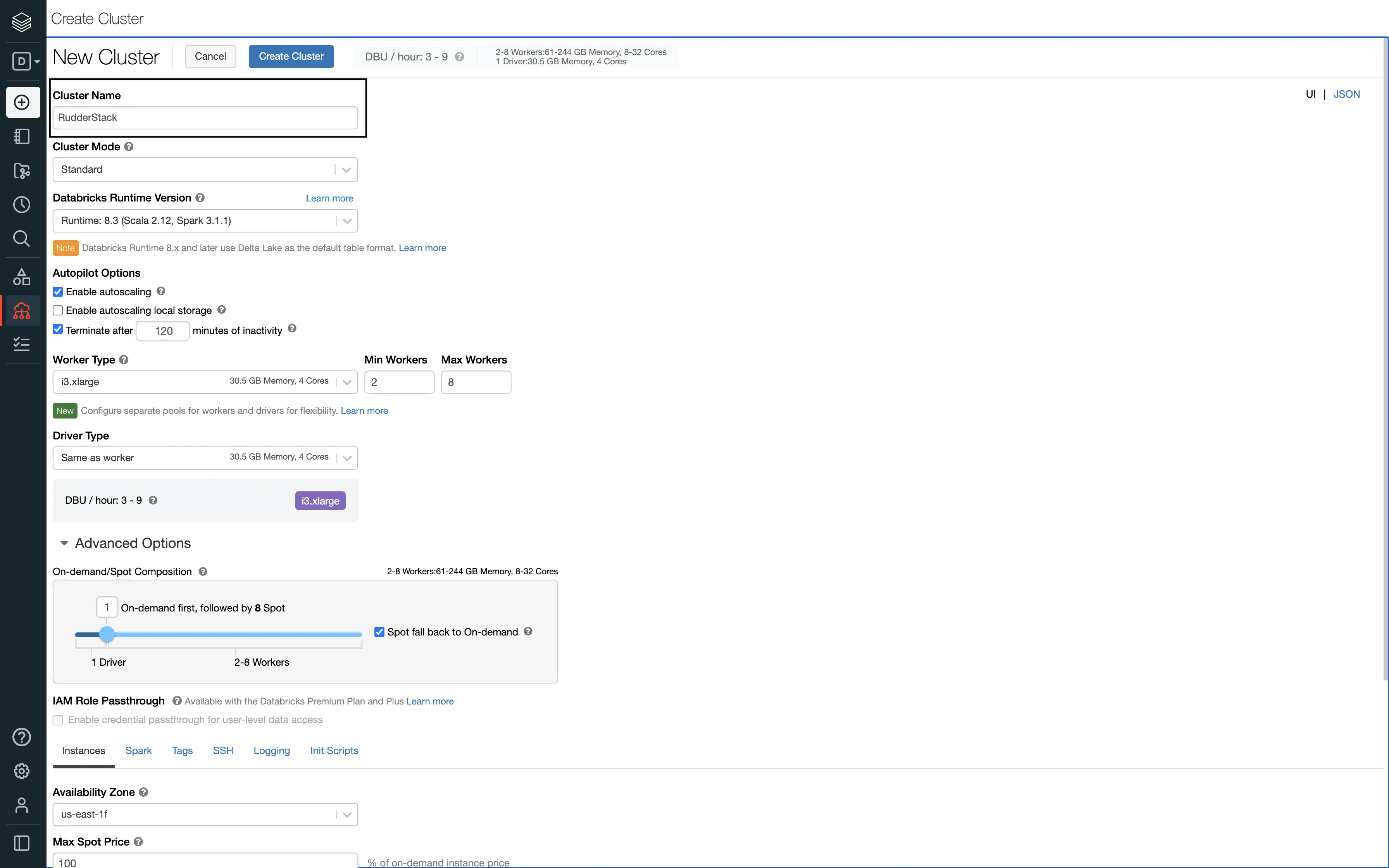
<storage-account-name>,<storage-account-access-key>.To create a new Databricks cluster, follow these steps:
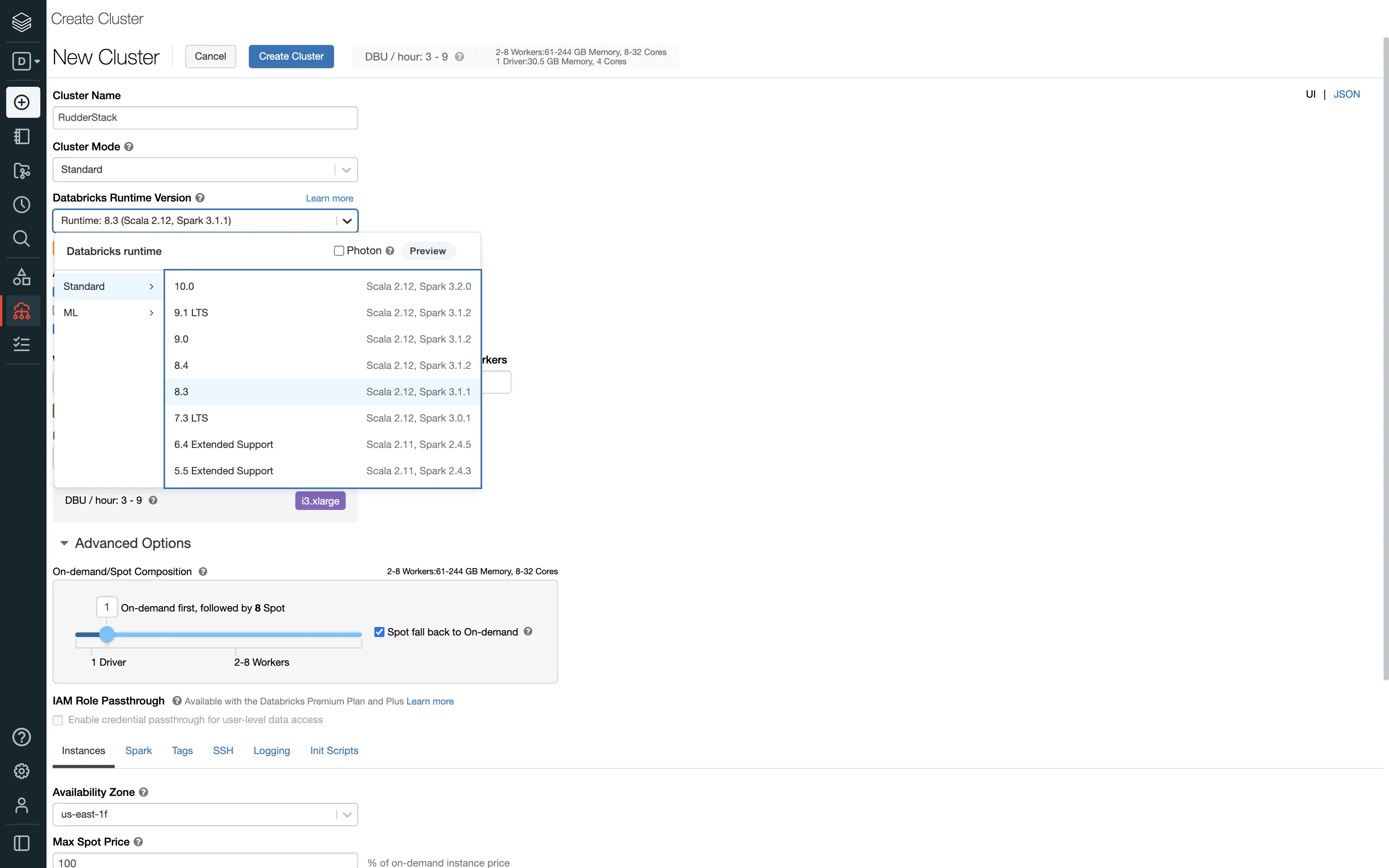
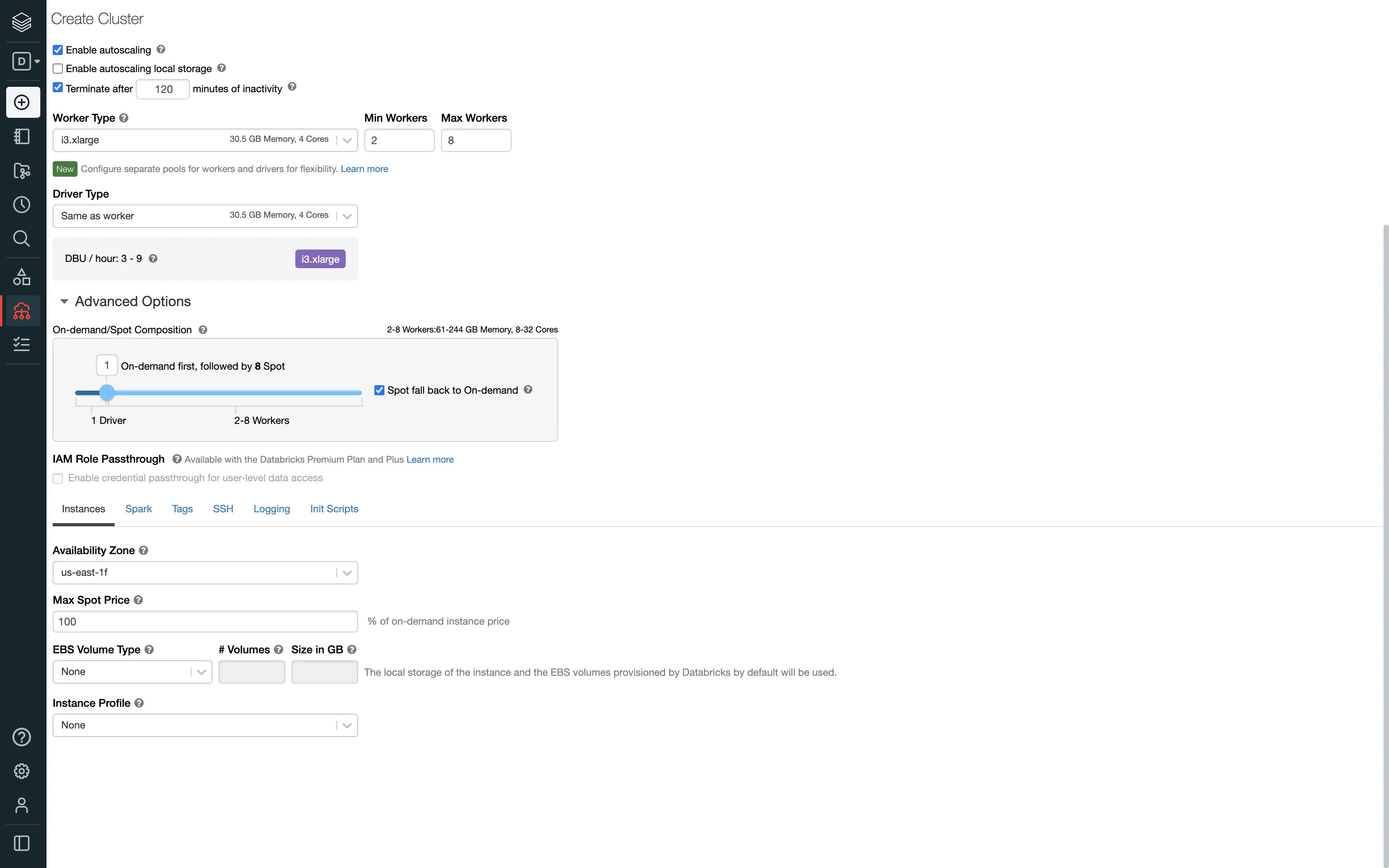
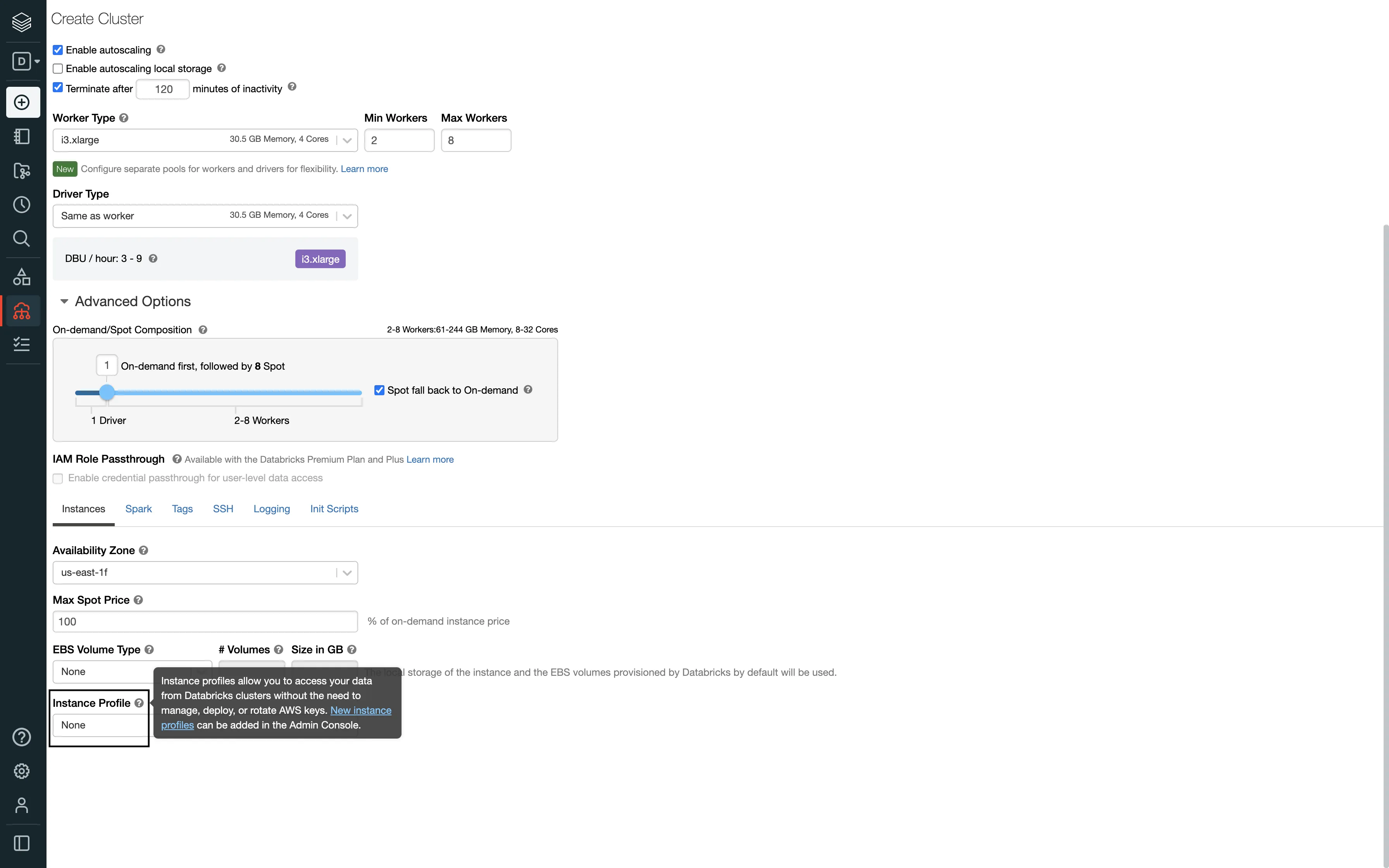
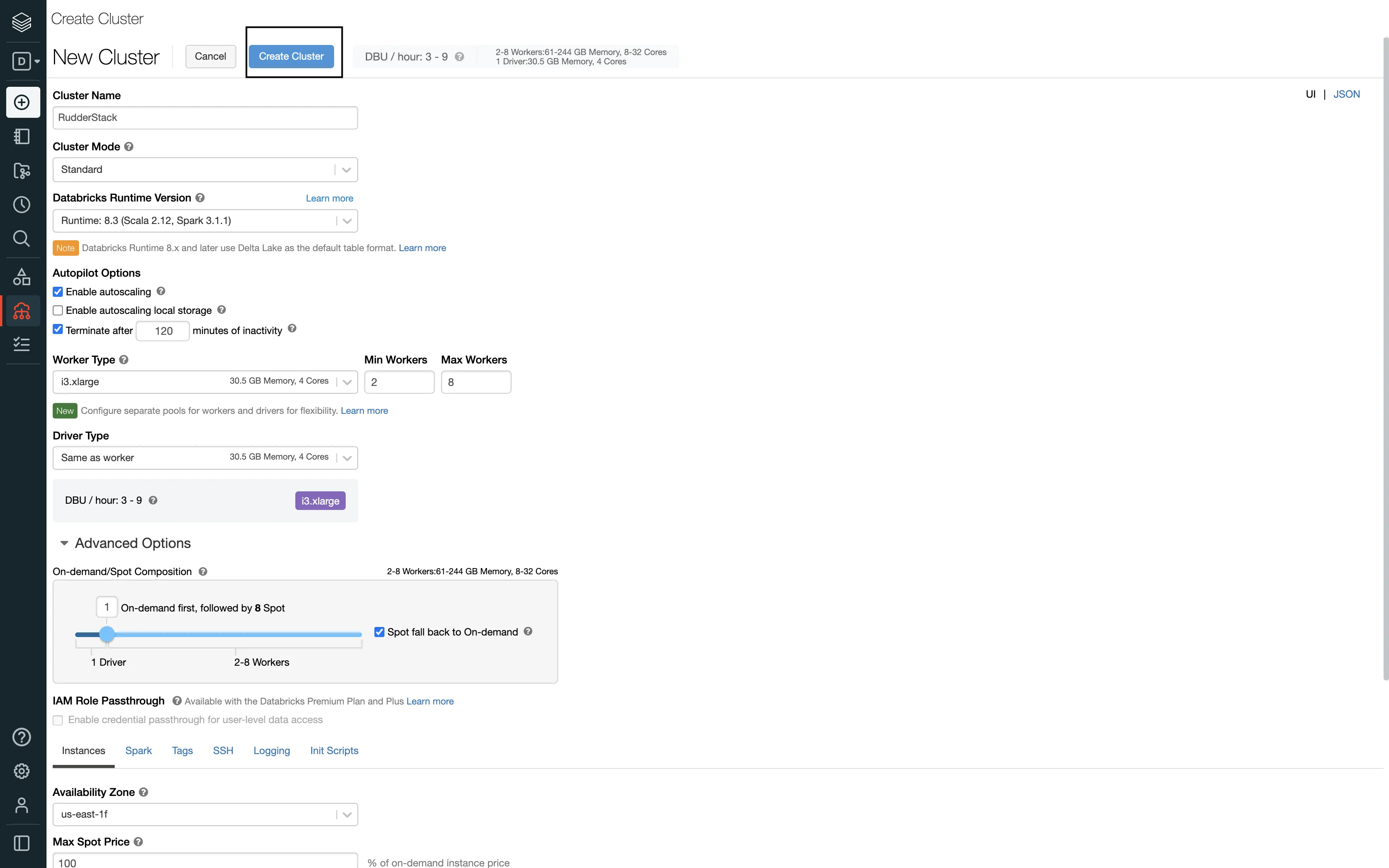
Follow these steps to get the JDBC/ODBC configuration:
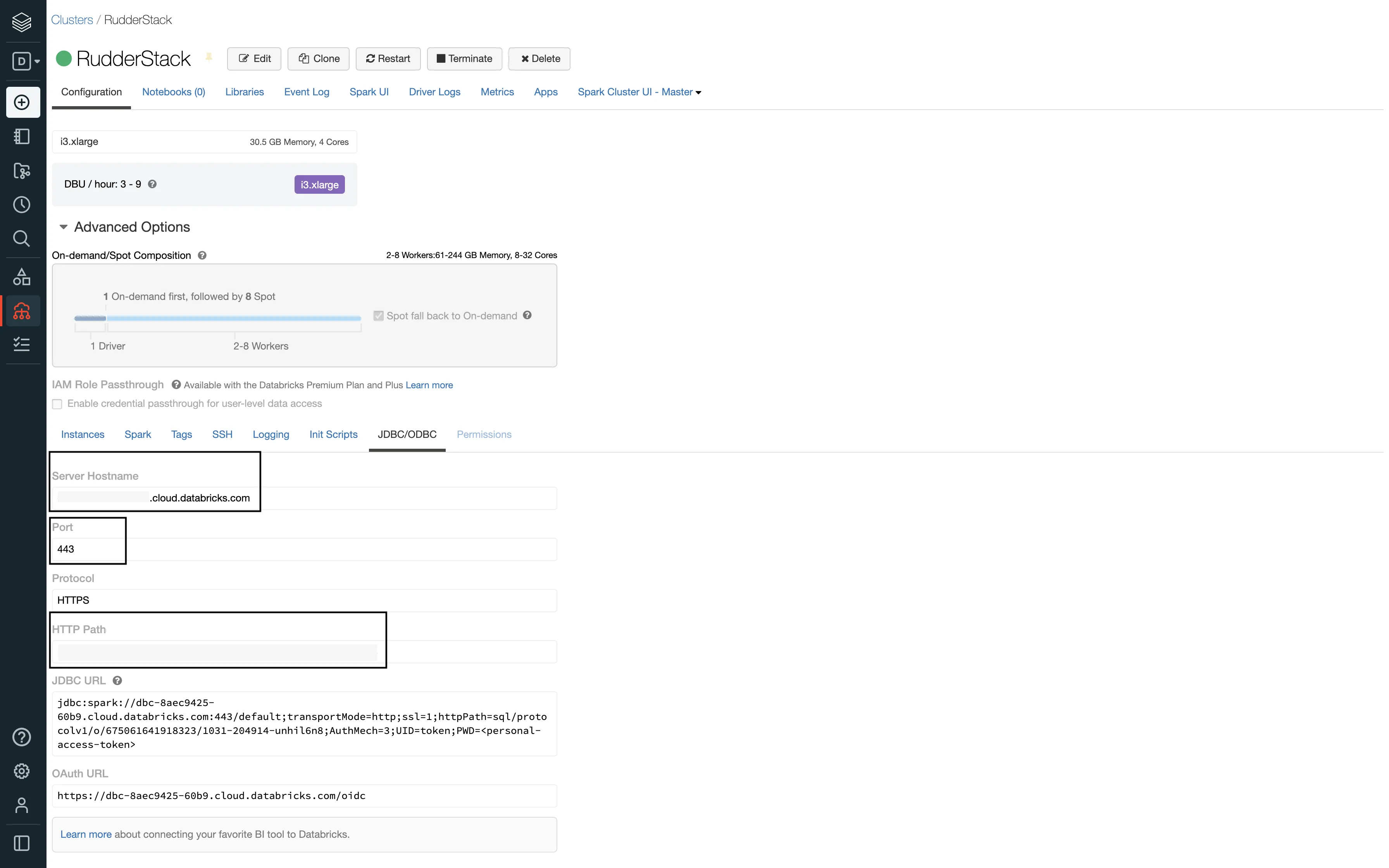
The Server Hostname, Port, and HTTP Path values are required to configure Delta Lake as a destination in RudderStack.
To generate the Databricks access token, follow these steps:
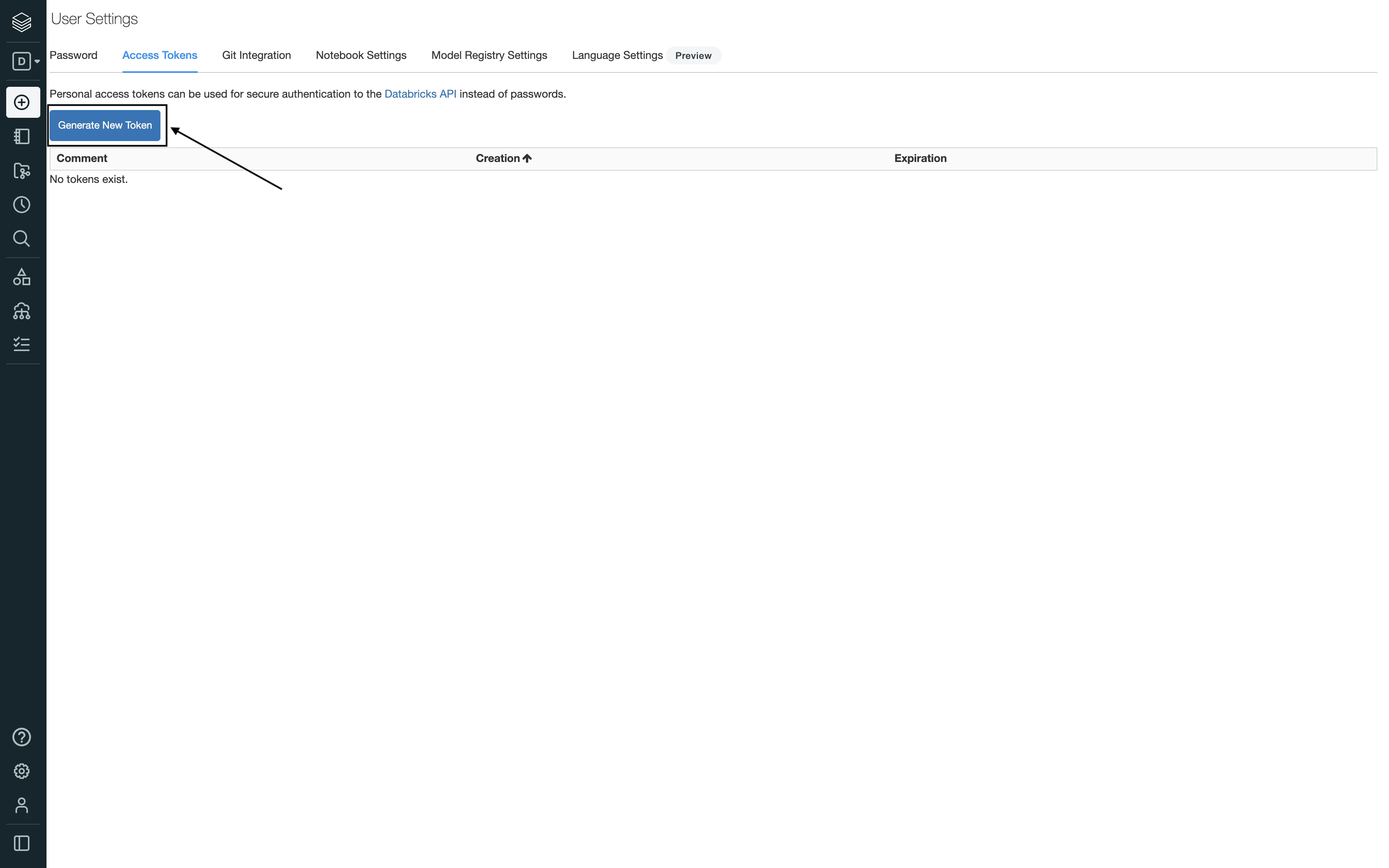
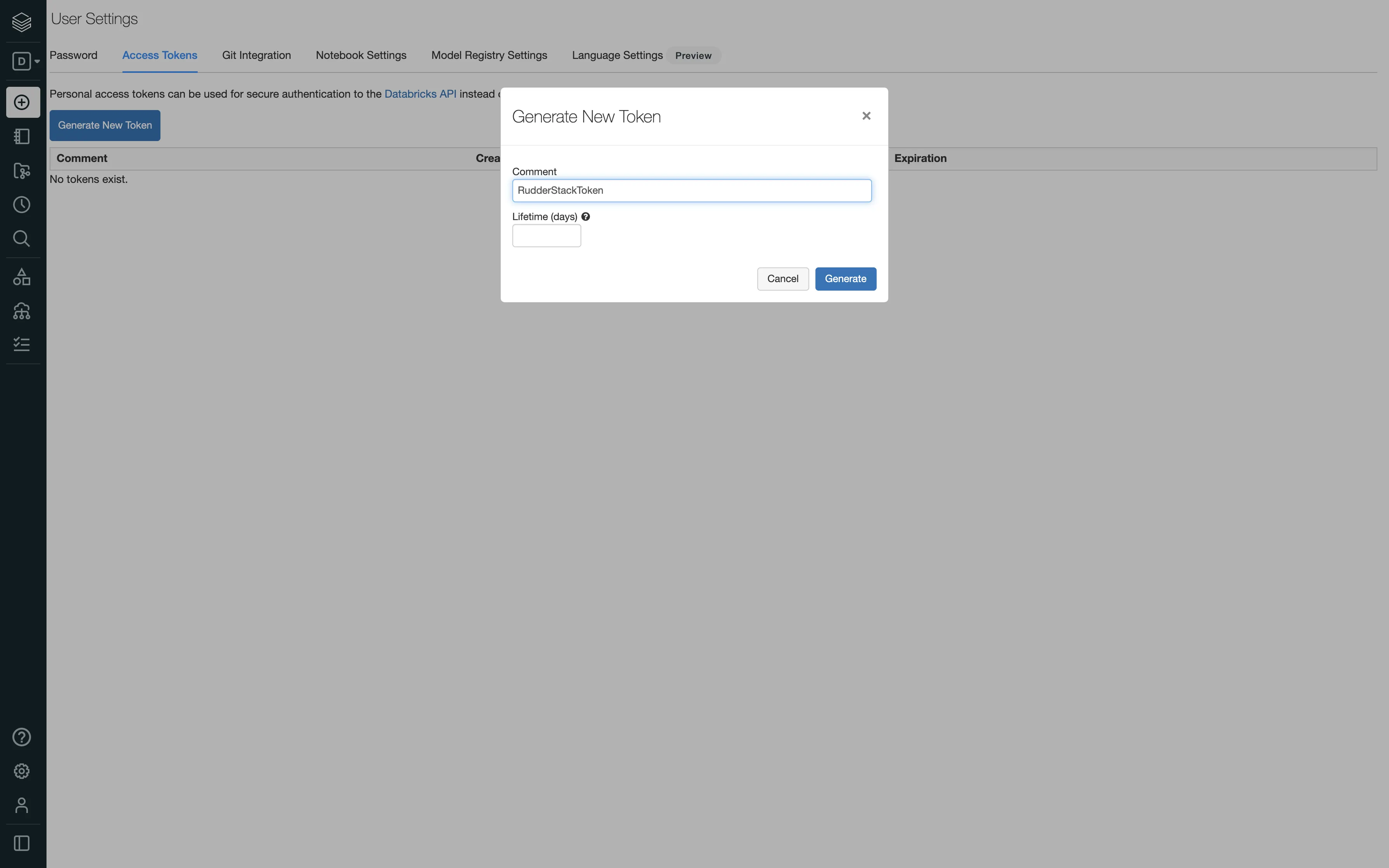
Keep the Lifetime (days) field blank. If you enter a number, your access token will expire after that number of days.
To enable network access to RudderStack, allowlist the following RudderStack IPs depending on your region and RudderStack Cloud plan:
| Plan | ||
|---|---|---|
| Free, Starter, and Growth |
|
|
| Enterprise |
|
|
All the outbound traffic is routed through these RudderStack IPs.
RudderStack takes the staging table and runs MERGE queries against the target Databricks tables to ensure no duplicate data is sent.
Refer to this documentation for a complete list of the reserved keywords.
No, your Databricks cluster attached to the destination need not be up all time.
If a warehouse destination is down or unavailable, RudderStack will continue to retry sending events (on an exponential backoff basis, for up to 3 hours).
RudderStack stores the syncs as staging files and retries sending them at a later time when the cluster is up again. This allows for a successful delivery without any missing data.
After retrying for up to 3 hours, RudderStack marks the syncs as aborted. Once the service is up and running again, you can go to the Syncs tab in the RudderStack dashboard and retry sending the data.
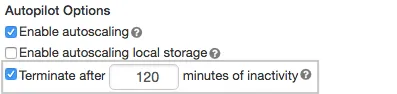
No, RudderStack does not spin the Databricks cluster or the SQL endpoint on its own every time it needs to write to the cluster.
Databricks itself starts up the cluster/endpoint when the connection is established. You just need to configure the automatic termination settings in the Autopilot Options on the cluster creation page:
There are some limitations when it comes to using reserved words as a schema, table, or column name. If such words are used in event names, traits or properties, they will be prefixed with a _ when RudderStack creates tables or columns for them in your schema.
Also, integers are not allowed at the start of a schema or table name. Hence, such schema, column, or table names will be prefixed with a _. For example, '25dollarpurchase' will be changed to '_25dollarpurchase'.
To modify an existing table to a partitioned table, follow these steps:
_temp suffix.event_date column to the _temp table.ALTER TABLE x RENAME TO x_temp;
ALTER TABLE x_temp ADD COLUMN TO event_date DATE;
INSERT INTO x SELECT * FROM x_temp;
RudderStack will create the new tables with partition support. Refer to the Databricks documentation on partitions for more information.
CREATE OR REPLACE TABLE namespace.x_temp DEEP CLONE namespace.x LOCATION '/path/to/new/location/namespace/x';
// where namespace represents the namespace attached to the destination in RudderStack.
// where x represents the original table created by RudderStack.
DROP TABLE namespace.x_temp;
DROP TABLE namespace.x;
RudderStack will create the table again during the subsequent data syncs.
Refer to the Databricks documentation on managed and unmanaged tables for more information.
CREATE TABLE IF NOT EXISTS namespace.x_temp DEEP CLONE namespace.x;
// where namespace represents the namespace attached to the destination in RudderStack.
// where x represents the original table created by RudderStack.
DROP TABLE namespace.x;
ALTER TABLE namespace.x_temp RENAME TO namespace.x;
RudderStack will create the table again during the subsequent data syncs.
For a more comprehensive FAQ list, refer to the Warehouse FAQ guide.
Connect your Databricks cluster to RudderStack and set up your Databricks Delta Lake destination.
Was this page helpful?
Glad to hear it! Please tell us how we can improve.
Sorry to hear that. Please tell us how we can improve.
Questions? Contact us by email or on Slack

