A sample pb_project.yaml file with entity type as user:
name:sample_attributionschema_version:54connection:testinclude_untimed:truemodel_folders:- modelsentities:- name:userid_types:- main_id- user_id- anonymous_id- emailpackages:- name:coreliburl:"https://github.com/rudderlabs/rudderstack-profiles-corelib/tag/schema_{{best_schema_version}}"# Profiles can also use certain model types defined in Python.# Examples include ML models. Those dependencies are specified here.python_requirements:- profiles-pycorelib==0.1.0
The following table explains the fields used in the above file:
Field
Data type
Description
name
String
Name of the project.
schema_version
Integer
Project’s YAML version. Each new schema version comes with improvements and added functionalities.
connection
String
Connection name from siteconfig.yaml used for connecting to the warehouse.
include_untimed
Boolean
Determines if inputs having no timestamps should be allowed. If true, data without timestamps is included when running the models.
Lists all the entities used in the project for which you can define models. Each entry for an entity here is a JSON object specifying entity’s name and attributes.
packages
List
List of packages with their name and URL. Optionally, you can also extend ID types filters for including or excluding certain values from this list.
List of all identifier types associated with the current entity.
The identifiers listed in id_types may have a many-to-one relationship with an entity but each ID must belong to a single entity.
For example, a user entity might have id_types as the salesforce_id, anonymous_id, email, and session_id (a user may have many session IDs over time). However, it should not include something like ip_address, as a single IP can be used by different users at different times and it is not considered as a user identifier.
packages
You can import library packages in a project signifying where the project inherits its properties from.
Field
Data type
Description
name
String
Specify a name.
url
String
HTTPS URL of the lib package, with a tag for the best schema version.
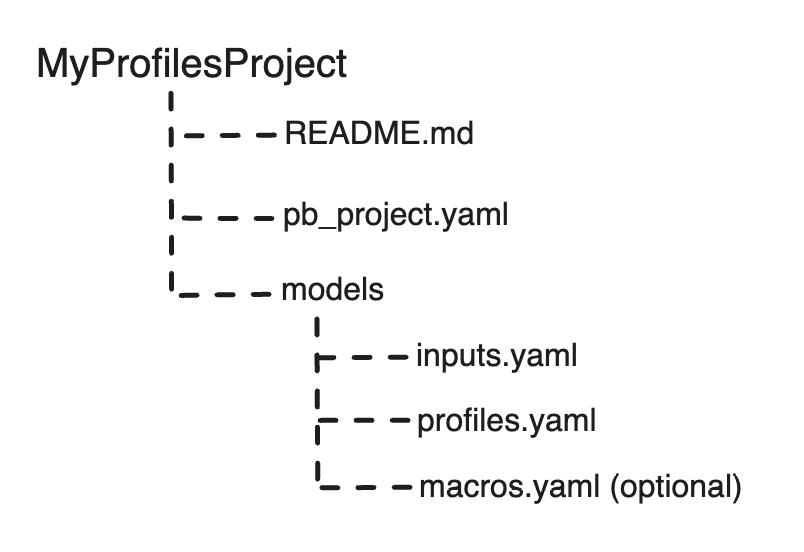
inputs.yaml
The inputs.yaml file lists all the input sources (tables/views) which should be used to obtain values for models and eventually create output tables.
It also specifies the table/view along with column name and SQL expression for retrieving values. The input specification may also include metadata, and the constraints on those columns.
A sample inputs.yaml file:
inputs:- name:salesforceTaskscontract:is_optional:falseis_event_stream:truewith_entity_ids:- userwith_columns:- name:activitydate- name:whoidapp_defaults:table:salesforce.task# For BigQuery, it is recommended to use view (view: _views_<view_name>) instead of table for event streaming data sets.occurred_at_col:activitydateids:# column name or sql expression- select:"whoid"type:salesforce_identity:userto_default_stitcher:true- name:salesforceContactcontract:is_optional:falseis_event_stream:truewith_entity_ids:- userwith_columns:- name:createddate- name:id- name:emailapp_defaults:table:salesforce.contact # For BigQuery, it is recommended to use view (view: _views_<view_name>) instead of table for event streaming data sets.occurred_at_col:createddateids:- select:"id"type:salesforce_identity:userto_default_stitcher:true- select:"case when lower(email) like any ('%gmail%', '%yahoo%') then lower(email) else split_part(lower(email),'@',2) end"type:emailentity:userto_default_stitcher:true- name:websitePageVisitscontract:is_optional:falseis_event_stream:truewith_entity_ids:- userwith_columns:- name:timestamp- name:anonymous_id- name:context_traits_email- name:user_idapp_defaults:table:autotrack.pages# For BigQuery, it is recommended to use view (view: _views_<view_name>) instead of table for event streaming data sets.occurred_at_col:timestampids:- select:"anonymous_id"type:rudder_anon_identity:userto_default_stitcher:true# below sql expression check the email type, if it is gmail and yahoo return email otherwise spilt email return domain of email. - select:"case when lower(coalesce(context_traits_email, user_id)) like any ('%gmail%', '%yahoo%') then lower(coalesce(context_traits_email, user_id)) \
else split_part(lower(coalesce(context_traits_email, user_id)),'@',2) end"type:emailentity:userto_default_stitcher:true
For BigQuery, RudderStack recommends you to use a view instead of table for streaming data sets.
The following table explains the fields used in the above file:
Field
Data type
Description
name
String
Name of the input model.
contract
Dictionary
A model contract provides essential information about the model like the necessary columns and entity IDs that it should contain. This is crucial for other models that depend on it, as it helps find errors early and closer to the point of their origin.
app_defaults
Dictionary
Values that input defaults to when you run the project directly. For library projects, you can remap the inputs and override the app defaults while importing the library projects.
contract
Field
Data type
Description
is_optional
Boolean
Whether the model’s existence in the warehouse is mandatory.
is_event_stream
Boolean
Whether the table/view is a series/stream of events. A model that has a timestamp column is an event stream model.
with_entity_ids
List
List of all entities with which the model is related. A model M1 is considered related to model M2 if there is an ID of model M2 in M1’s output columns.
with_columns
List
List of all ID columns that this contract is applicable for.
app_defaults
Field
Data type
Description
table/view
String
Name of the warehouse table/view containing the data. You can prefix the table/view with an external schema or database in the same warehouse, if applicable. Note that you can specify either a table or view but not both.
occurred_at_col
String
Name of the column in table/view containing the timestamp.
Specifies the list of all IDs present in the source table along with their column names (or column SQL expressions).
Note: Some input columns may contain IDs of associated entities. By their presence, such ID columns associate the row with the entity of the ID. The ID Stitcher may use these declarations to automatically discover ID-to-ID edges.
ids
Field
Data type
Description
select
String
Specifies the column name to be used as the identifier. You can also specify a SQL expression if some transformation is required.
Note: You can also refer table from another Database/Schema in the same data warehouse. For example, table: <database_name>.<schema_name>.<table_name>.
type
String
Type of identifier. All the ID types of a project are declared in pb_project.yaml. You can specify additional filters on the column expression.
Note: Each ID type is linked only with a single entity.
entity
String
Entity name defined in the pb_project.yaml file to which the ID belongs.
to_default_stitcher
Boolean
Set this optional field to false for the ID to be excluded from the default ID stitcher.
profiles.yaml
The profiles.yaml file lists entity_vars / input_vars used to create the output tables under var_groups:.
Field
Data type
Description
name
String
A unique name for the var_group.
entity_key
String
The entity to which the var_group belongs to.
vars
Object
This section is used to specify variables, with the help of entity_var and input_var. Aggregation on stitched ID type is done by default and is implicit.
Optionally, you can create models using the above vars. The following fields are common for all the model types:
Field
Data type
Description
name
String
Name of the model. Note that a table with the same name is created in the data warehouse. For example, if you define the name as user_table, the output table will be named something like Material_user_table_<rest-of-generated-hash>_<timestamp-number>.
model_type
String
Defines the type of model. Possible values are: id_stitcher, feature_table_model, and sql_template.
model_spec
Object
Creates a detailed configuration specification for the target model. Different schema is applicable for different model types as explained in each section below.
This site uses cookies to improve your experience while you navigate through the website. Out of
these
cookies, the cookies that are categorized as necessary are stored on your browser as they are as
essential
for the working of basic functionalities of the website. We also use third-party cookies that
help
us
analyze and understand how you use this website. These cookies will be stored in your browser
only
with
your
consent. You also have the option to opt-out of these cookies. But opting out of some of these
cookies
may
have an effect on your browsing experience.
Necessary
Always Enabled
Necessary cookies are absolutely essential for the website to function properly. This
category only includes cookies that ensures basic functionalities and security
features of the website. These cookies do not store any personal information.
This site uses cookies to improve your experience. If you want to
learn more about cookies and why we use them, visit our cookie
policy. We'll assume you're ok with this, but you can opt-out if you wish Cookie Settings.